
















BERT Dil Modeli Nedir ?

BERT, doğal dil işleme (NLP) için açık kaynaklı bir makine öğrenimi çerçevesidir . BERT, bağlam oluşturmak için çevreleyen metni kullanarak bilgisayarların metindeki belirsiz dilin anlamını anlamasına yardımcı olmak için tasarlanmıştır. BERT çerçevesi, Wikipedia'dan alınan metin kullanılarak önceden eğitilmiştir ve soru ve yanıt veri kümeleriyle ince ayar yapılabilir.
Transformers'tan Çift Yönlü Kodlayıcı Temsilleri anlamına gelen BERT, her çıkış öğesinin her giriş öğesine bağlandığı ve aralarındaki ağırlıkların bağlantılarına göre dinamik olarak hesaplandığı derin bir öğrenme modeli olan Transformers'a dayanmaktadır. (NLP'de bu sürece dikkat denir .)
Tarihsel olarak, dil modelleri metin girişini yalnızca sırayla (soldan sağa veya sağdan sola) okuyabiliyordu, ancak ikisini aynı anda yapamıyordu. BERT farklıdır çünkü aynı anda her iki yönde okumak için tasarlanmıştır. Transformers'ın kullanıma sunulmasıyla etkinleştirilen bu yetenek, çift yönlülük olarak bilinir.
Bu çift yönlü yeteneği kullanan BERT, iki farklı ama birbiriyle ilişkili NLP görevi için önceden eğitilmiştir: Maskeli Dil Modelleme ve Sonraki Cümle Tahmini.
Maskeli Dil Modeli (MLM) eğitiminin amacı, bir kelimeyi bir cümle içinde gizlemek ve ardından programın, gizli kelimenin bağlamına göre hangi kelimenin gizlendiğini (maskelendiğini) tahmin etmesini sağlamaktır. Sonraki Cümle Tahmini eğitiminin amacı, programın verilen iki cümlenin mantıksal, sıralı bir bağlantısı olup olmadığını veya ilişkilerinin rastgele olup olmadığını tahmin etmesini sağlamaktır.
Arka plan
Transformatörler ilk olarak 2017'de Google tarafından tanıtıldı. Tanıtıldıkları sırada dil modelleri, NLP görevlerini yerine getirmek için öncelikle tekrarlayan sinir ağları ( RNN ) ve evrişimli sinir ağları ( CNN ) kullanıyordu.
Bu modeller yetkin olsa da, RNN'ler ve CNN'ler bunu yaparken veri dizilerinin herhangi bir sabit sırada işlenmesini gerektirmediği için Transformer önemli bir gelişme olarak kabul edilir. Transformers, verileri herhangi bir sırayla işleyebildiği için, var olmadan önce mümkün olandan çok daha fazla miktarda veri üzerinde eğitim sağlar. Bu da, yayınlanmadan önce büyük miktarda dil verisi üzerinde eğitilen BERT gibi önceden eğitilmiş modellerin oluşturulmasını kolaylaştırdı.
2018'de Google, BERT'yi tanıttı ve açık kaynaklı hale getirdi. Araştırma aşamalarında çerçeve, duygu analizi , anlamsal rol etiketleme, cümle sınıflandırması ve çok anlamlı sözcüklerin veya birden çok anlama sahip sözcüklerin belirsizliğini giderme dahil olmak üzere 11 doğal dil anlama görevinde çığır açan sonuçlar elde etti.
Bu görevlerin tamamlanması, BERT'yi bağlam ve çok anlamlı sözcükleri yorumlarken sınırlı olan word2vec ve GloVe gibi önceki dil modellerinden ayırdı. BERT , alandaki araştırmacı bilim adamlarına göre doğal dili anlamanın önündeki en büyük zorluk olan belirsizliği etkili bir şekilde ele alıyor . Nispeten insan benzeri bir "sağduyu" ile dili ayrıştırma yeteneğine sahiptir.
Ekim 2019'da Google, Amerika Birleşik Devletleri merkezli üretim arama algoritmalarına BERT uygulamaya başlayacaklarını duyurdu.
BERT'nin Google arama sorgularının %10'unu etkilemesi bekleniyor. BERT doğal bir arama deneyimi sağlamayı amaçladığından, kuruluşların içeriği BERT için denememesi ve optimize etmemesi önerilir. Kullanıcılara, sorguları ve içeriği doğal konuya ve doğal kullanıcı deneyimine odaklamaları önerilir.
Aralık 2019'da BERT, 70'ten fazla farklı dile uygulandı.
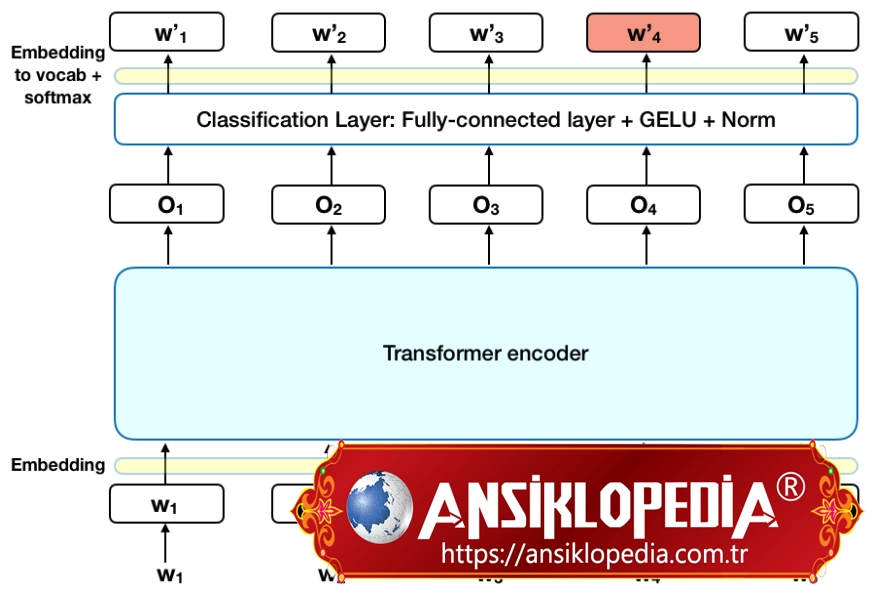
BERT nasıl çalışır?
Herhangi bir NLP tekniğinin amacı, insan dilini doğal olarak konuşulduğu şekliyle anlamaktır. BERT'nin durumunda, bu tipik olarak bir kelimeyi boşlukta tahmin etmek anlamına gelir. Bunu yapmak için, modellerin genellikle özel, etiketli eğitim verilerinin büyük bir havuzunu kullanarak eğitilmesi gerekir. Bu , dilbilimci ekipleri tarafından zahmetli manuel veri etiketlemeyi gerektirir.
Ancak BERT, yalnızca etiketlenmemiş, düz metin bir külliyat (yani İngilizce Wikipedia'nın tamamı ve Brown Corpus) kullanılarak önceden eğitildi. Pratik uygulamalarda (ör. Google arama) kullanılsa da denetimsiz olarak etiketlenmemiş metinden öğrenmeye ve gelişmeye devam ediyor. Ön eğitimi, inşa edilecek temel bir "bilgi" katmanı görevi görür. Buradan BERT, sürekli büyüyen aranabilir içerik ve sorgulara uyum sağlayabilir ve kullanıcının özelliklerine göre ince ayar yapabilir. Bu süreç transfer öğrenimi olarak bilinir .
Yukarıda bahsedildiği gibi BERT, Google'ın Transformers üzerine yaptığı araştırma sayesinde mümkün olmuştur. Dönüştürücü, modelin BERT'ye dildeki bağlamı ve belirsizliği anlama kapasitesini artıran kısmıdır. Dönüştürücü bunu, herhangi bir kelimeyi birer birer işlemek yerine bir cümledeki diğer tüm kelimelerle ilişkili olarak işleyerek yapar. Transformer, çevredeki tüm kelimelere bakarak, BERT modelinin kelimenin tam bağlamını anlamasına ve dolayısıyla arama yapanın amacını daha iyi anlamasına olanak tanır.
Bu, GloVe ve word2vec gibi önceki modellerin her bir kelimeyi, o kelimenin anlamının yalnızca bir boyutunu, bir şeridini temsil eden bir vektöre eşlediği, kelime gömme olarak bilinen geleneksel dil işleme yöntemiyle çelişir.
Bu kelime gömme modelleri, büyük etiketli veri veri kümeleri gerektirir. Birçok genel NLP görevinde usta olsalar da, soru yanıtlamanın bağlam ağırlıklı, tahmine dayalı doğasında başarısız olurlar, çünkü tüm kelimeler bir anlamda bir vektöre veya anlama sabitlenmiştir. BERT, kelimenin "kendini görmesini" - yani bağlamından bağımsız sabit bir anlama sahip olmasını - odakta tutmak için bir maskelenmiş dil modelleme yöntemi kullanır. BERT daha sonra yalnızca bağlama dayalı olarak maskelenmiş sözcüğü tanımlamaya zorlanır. BERT'de kelimeler, ön sabit bir kimlikle değil, çevreleri tarafından tanımlanır. İngiliz dilbilimci John Rupert Firth'ün sözleriyle, "Sahip olduğu şirketten bir kelime bileceksiniz."




-
0 Yorum
-
18 Görüntülenme

















